Abstract
Digital-avatar systems still provide limited control over emotionally expressive behavior in human-computer interaction,
especially in LLM-based chatbots and virtual assistants with personalized visual embodiments. To address this problem,
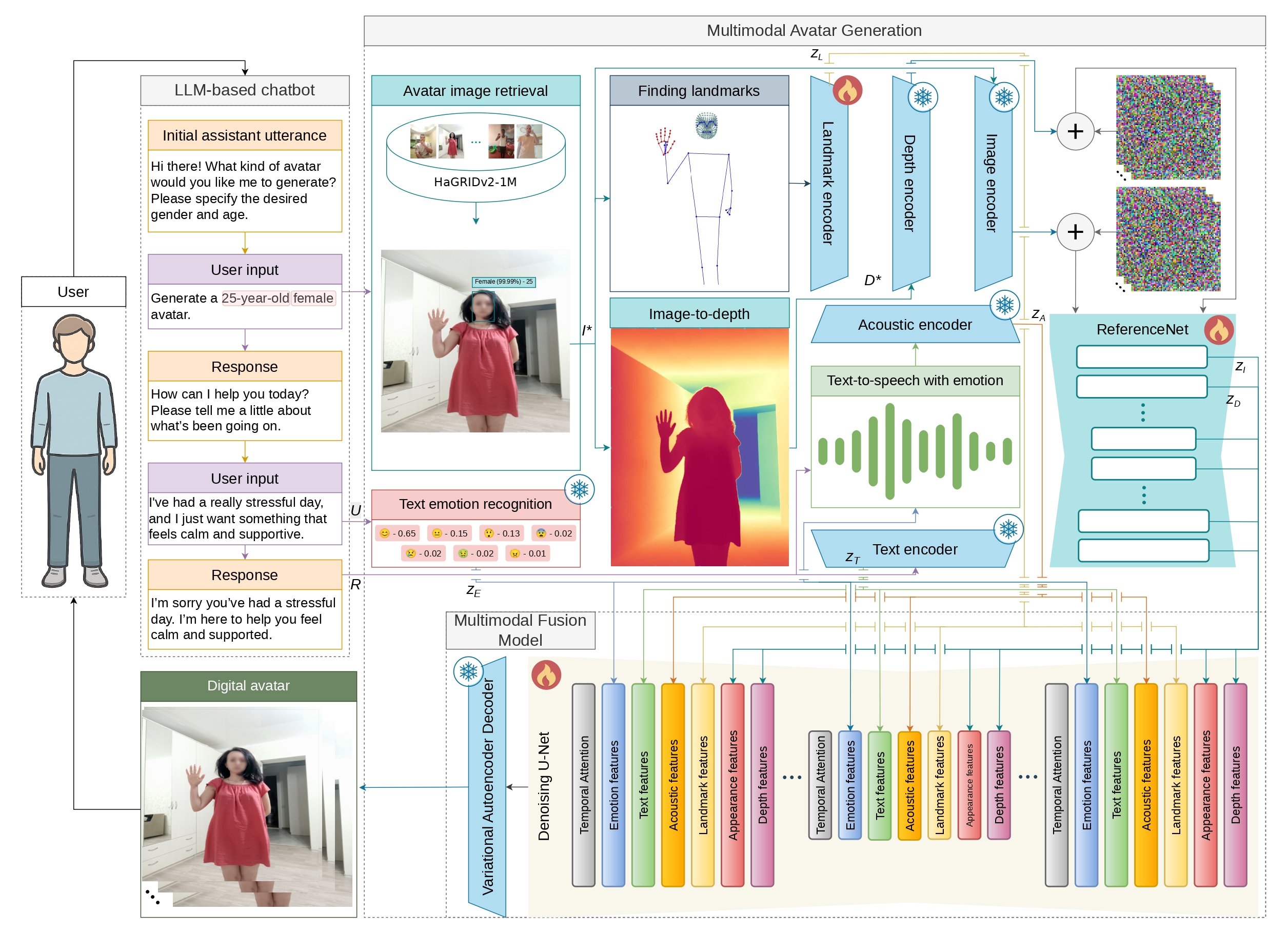
we propose MAVAGEN, a multimodal avatar generation framework for synthesizing upper-body digital avatars with personalized
appearance and controllable emotional expression. The user specifies the desired gender and age, and provides a short text
input from which the target emotional state is inferred. MAVAGEN retrieves an identity image from the HaGRIDv2-1M corpus
and generates an avatar clip with synchronized facial expressions, hand gestures, and expressive speech.
The framework uses six feature streams: textual features, emotion-distribution features, landmark-based pose features,
depth-geometry features, RGB-appearance features, and acoustic features. In quantitative evaluation against recent human
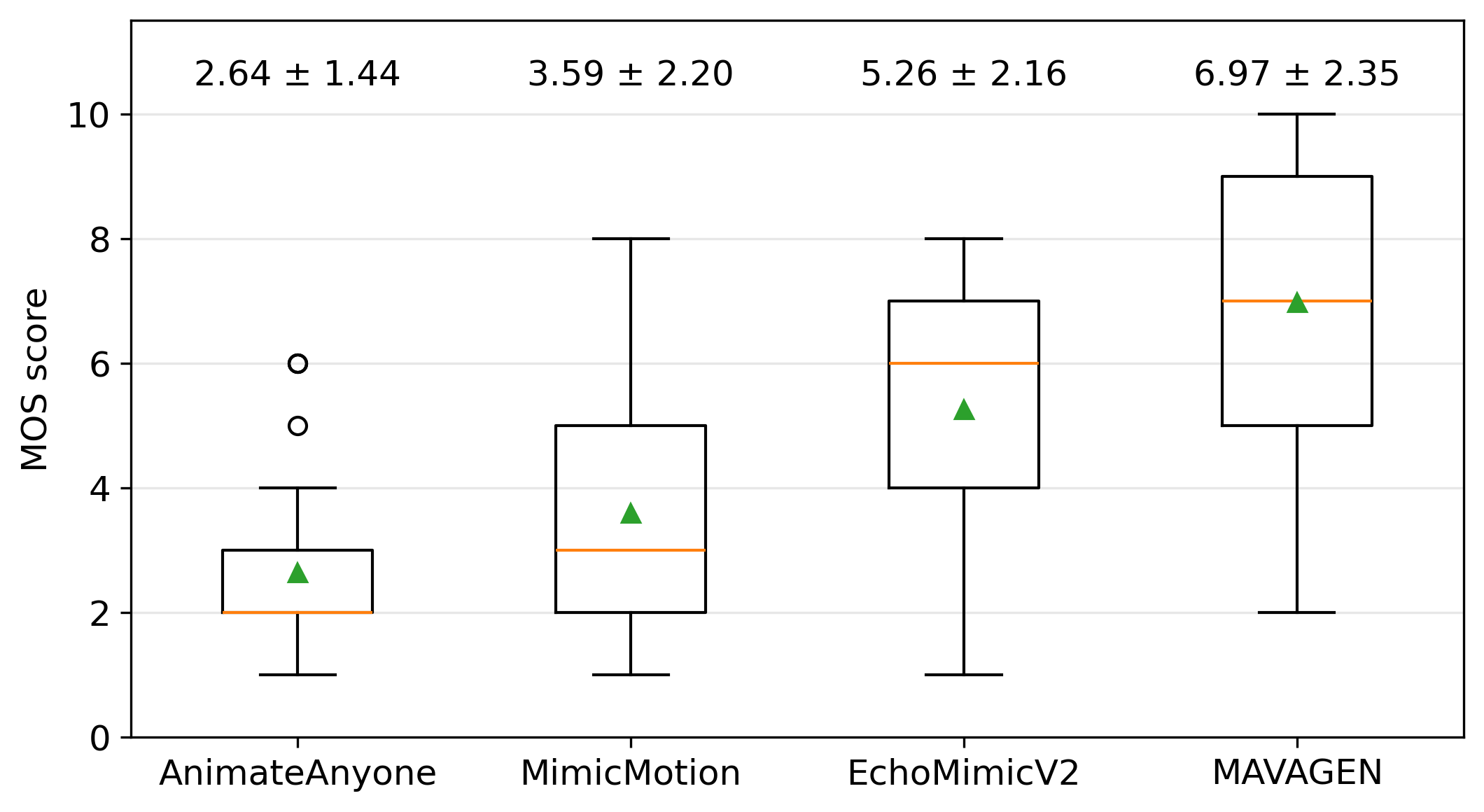
animation methods, MAVAGEN achieves the best overall avatar quality, with FID 48.20, FVD 592.00, SSIM 0.741, Sync-C 7.40,
HKC 0.929, HKV 25.30, CSIM 0.563, EmoAcc 0.88, and MOS 6.97.